위급 상황 대응 시스템을 개발하기 위해 필요한 주요 기능 중 하나는 사용자가 녹음한 음성 데이터에서 텍스트를 추출하는 작업이 필요하였습니다. 이러한 작업을 위해 AWS에서 제공하는 AWS Transcribe 서비스를 통해 개발하는 과정을 기록하였습니다.
주요 환경
- 런타임 플랫폼 : Node.js
- 언어 : Typescript
- 웹 프레임워크 : NestJS
주요 환경에 있는 거처럼 타입스크립트의 웹프레임워크인 Nest.js를 통해 서버를 구현하였습니다. 따라서 주요 타입스크립트와 NestJS의 기능들이 많이 등장하지만 이번 글을 타입스크립트나 NestJS를 설명하는 글이 아니기 때문에 자세한 설명은 생략하도록 하겠습니다.
왜 AWS Transcribe를 사용하였는가
우선 여러 클라우드 서비스에서 텍스트 추출 기능을 제공합니다. 구글 GCP의 Speech-to-Text, 네이버 NCP의 CLOVA Speech 등이 있습니다. 이 중에서 AWS의 Transcribe를 사용한 가장 큰 이유는 음성 데이터를 S3에 저장하고 AWS Transcribe에서 저장된 S3 객체를 키값을 통해 바로 가져올 수 있다는 점이었습니다. 또한 AWS 프리티어도 적용 가능합니다.
NestJS - S3 객체 업로드
우선 AWS Trancsribe를 사용하기 위해 S3에 음성 데이터를 업로드해야 합니다.
이를 위해 첫번째로 음성 데이터를 저장할 S3 버킷을 생성합니다.
저희 프로젝트에선 음성 데이터를 모바일 앱에서도 접근해야 되기 때문에, 퍼블릭으로 설정하였습니다.
자세한 버킷 생성 방법은 아래 링크를 참고해주세요.
NestJS 에서 파일 업로드를 처리하기 위해서 multer 미들웨어를 사용합니다.
Multer는 주로 파일 업로드에 사용되는 multipart/form-data 를 처리하기 위한 미들웨어입니다.
그리고 NestJS에서는 multer 기반의 파일 업로드 인터셉터(Intercepter)를 기본으로 제공합니다. 인터셉터는 간단히 말해 Node.js의 middleware 중 하나의 형태라고 생각하면 됩니다. Intercepter의 자세한 내용은 아래 링크를 참고해주세요.
❗ NestJS에서 request와 response가 HTTP 위에서 동작하게 설계되어 있기 때문에 HTTP 통신이 아니면 사용이 불가합니다. 반면에 Interceptor는 파라미터로 execution context라는 helper class를 받아 처리하기 때문에 HTTP 이외에도 WebSocket, GraphQL, RPC(Remote procedure call) 위에서도 동작 가능합니다.
이 외에도 Middleware, Guards, Interceptors, Pipes, Filters는 기술적으로 모두 NodeJS에서 말하는 Middleware에 속하지만, NestJS에선 Guards, Interceptors, Pipes, Filters를 enhancer라고 부르며, 꼭 Middleware가 필요한 경우가 아니라면 enhancer 쓰길 권장하고 있습니다.
참고 : https://blog-ko.superb-ai.com/nestjs-interceptor-and-lifecycle/
아래 코드는 음성 데이터를 처리하는 controller입니다.
//report.controller.ts
@UseGuards(AuthGuard)
@Post('')
@UseInterceptors(FileInterceptor('file'))
async uploadAudio(@Headers() headers: any, @UploadedFile() file: Express.Multer.File, @Res() res: Response,) {
try {
const uploadAudioResult = await this.reportService.uploadAudio(
file.buffer,
file.originalname,
);
console.log('uploadAudioResult', uploadAudioResult);
const textExtractionResult = await this.reportService.textExtraction(
uploadAudioResult,
report,
);
console.log('textExtractionResult', textExtractionResult);
...
} catch (e) {
...
}
}
클라이언트에서 해당 API를 사용하여 음성 데이터를 전송하면 file 객체의 내부 구조는 아래와 같습니다.

이러한 데이터에서 S3에 전송해야 하는 부분은 buffer 키입니다. 그리고 음성 데이터의 구분을 위해 originalname 키를 사용하였습니다. 두 값을 reportService의 uploadAudio 메서드로 넘겨줍니다.
//report.service.ts
...
import * as AWS from 'aws-sdk';
import {
TranscribeClient,
StartTranscriptionJobCommand,
TranscriptionJob,
GetTranscriptionJobCommand,
GetTranscriptionJobCommandOutput,
} from '@aws-sdk/client-transcribe';
@Injectable()
export class ReportService {
private readonly s3: AWS.S3;
constructor(
...
) {
AWS.config.update({
region: this.config.get('AWS_REGION'),
credentials: {
accessKeyId: this.config.get('AWS_ACCESS_KEY'),
secretAccessKey: this.config.get('AWS_SECRET_KEY'),
},
});
this.s3 = new AWS.S3();
}
async uploadAudio(dataBuffer: Buffer, fileName: string): Promise<any> {
try {
const key = `Audio/${Date.now()}-${fileName}`;
const params: AWS.S3.PutObjectRequest = {
Bucket: this.config.get('AWS_BUCKET_NAME'),
ACL: 'public-read',
Key: key,
Body: dataBuffer,
};
const uploadResult = await this.s3.upload(params).promise();
return {
fileName: fileName,
fileUrl: uploadResult.Location,
s3_key: uploadResult.Key,
};
} catch (e) {
console.log(e);
...
}
}
}
저희 프로젝트에서는 S3를 사용하는 서비스가 reportService 한 곳이기 때문에, s3 객체를 reportService 의 클래스 변수로 설정하였습니다. 만약 여러 서비스나 모듈에서 사용한다면, NestJS의 Module로 설정하거나 Custom Provider로 설정하길 바랍니다.
업로드 결과로 아래 콘솔 화면과 같이 정상적으로 저장된 것을 확인할 수 있습니다. fileUrl의 경우 AWS 웹 콘솔에서 확인하면 정상적인 한글로 저장됩니다. AWS Transcribe에서는 s3_key 키를 통해 해당 객체를 접근합니다.

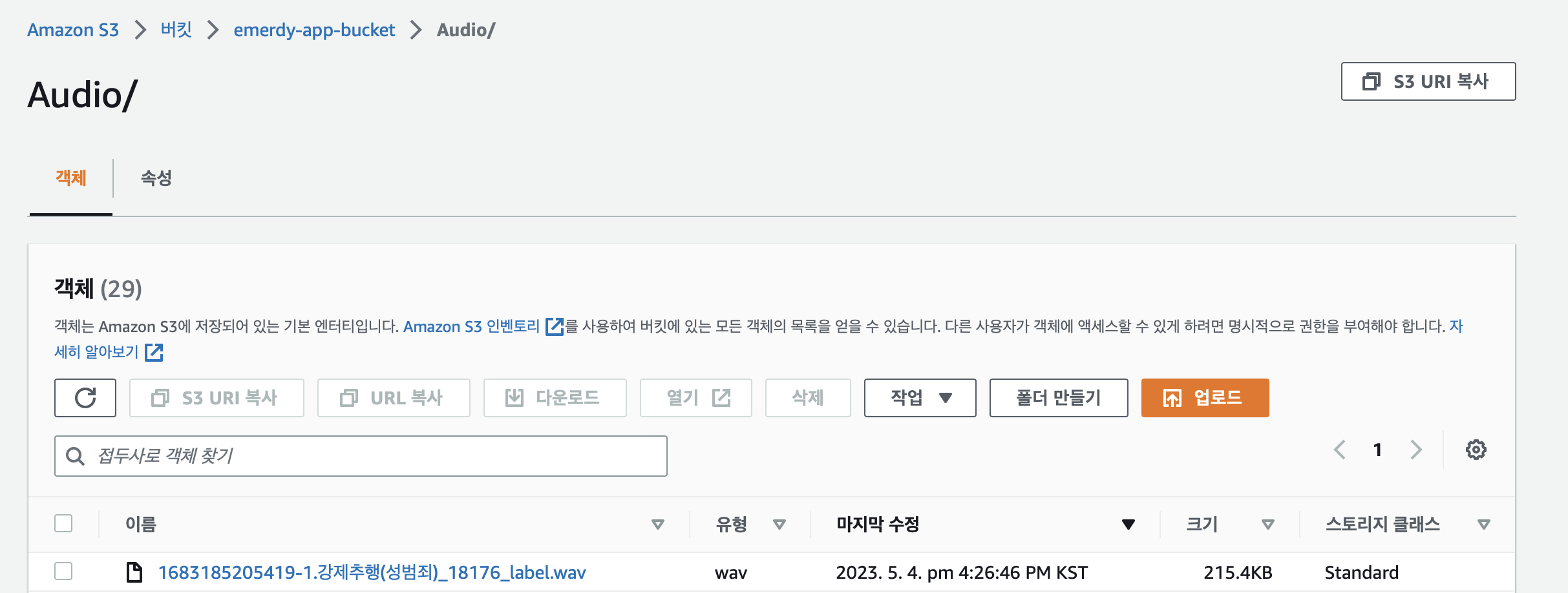
S3 객체 Key로 AWS Transcribe 실행
AWS Transcribe의 주요 작업 순서는 다음과 같습니다.
- transcribeClient 객체 생성
- Transcribe 작업 시작
- Transcribe 작업 완료 여부 체크
- 작업 완료 시, output인 JSON S3 객체 조회
우선 AWS Transcribe를 Node.js상에서 실행하기 위해 aws-sdk를 설치합니다.
npm install @aws-sdk/client-transcribe
async textExtraction(s3Object: any, report: Report): Promise<string> {
try {
const transcribeConfig = {
region: this.config.get('AWS_REGION'),
credentials: {
accessKeyId: this.config.get('AWS_ACCESS_KEY'),
secretAccessKey: this.config.get('AWS_SECRET_KEY'),
},
};
const transcribeClient = new TranscribeClient(transcribeConfig);
const transcriptionJobResponse = await this.sendTranscribeJob(
transcribeClient,
s3Object,
report,
);
console.log('transcriptionJobResponse', transcriptionJobResponse);
const successTranscribe = await this.getTranscribeResult(
transcribeClient,
transcriptionJobResponse.TranscriptionJobName,
);
console.log('successTranscribe', successTranscribe);
console.log(successTranscribe.TranscriptionJobName);
const script = await this.getTranscriptFile(successTranscribe.TranscriptionJobName);
return script; // results.transcripts[0].transcript
} catch (e) {
console.log(e);
...
}
}
Transcribe 작업 시작
private async sendTranscribeJob(transcribeClient: TranscribeClient, s3Object: any, report: Report): Promise<TranscriptionJob> {
try {
const params = {
TranscriptionJobName: `${Date.now()}-${report.id}`,
LanguageCode: 'ko-KR',
MediaFormat: 'wav',
Media: {
MediaFileUri: `https://s3-ap-northeast-2.amazonaws.com/${this.config.get('AWS_BUCKET_NAME',)}/${s3Object.s3_key}`,
},
OutputBucketName: 'emerdy-app-audio-transcribe-output',
};
const transcribeCommand = new StartTranscriptionJobCommand(params);
const transcriptionJobResponse = await transcribeClient.send(transcribeCommand);
return transcriptionJobResponse.TranscriptionJob;
} catch (e) {
console.log(e);
...
}
}
Transcribe의 작업 이름은 반드시 Unique해야 합니다. 따라서 전 UTC 밀리초와 해당 음성데이터의 신고 id를 합쳐 작업 이름을 설정하였습니다.
LanguageCode를 통해 추출할 음성 텍스트의 언어를 설정합니다.
MediaFormat은 multer를 통해 얻은 mimetype 값을 입력하면 됩니다.
그리고 Media키의 MediaFileUri을 통해 S3 객체의 키를 입력합니다.
그외 파라미터에 대한 설명은 아래 AWS API Document를 참고해주세요.
StartTranscriptionJobCommand @aws-sdk/client-transcribe
위 메서드를 실행하면 응답 결과로 TranscriptionJob을 확인할 수 있습니다.
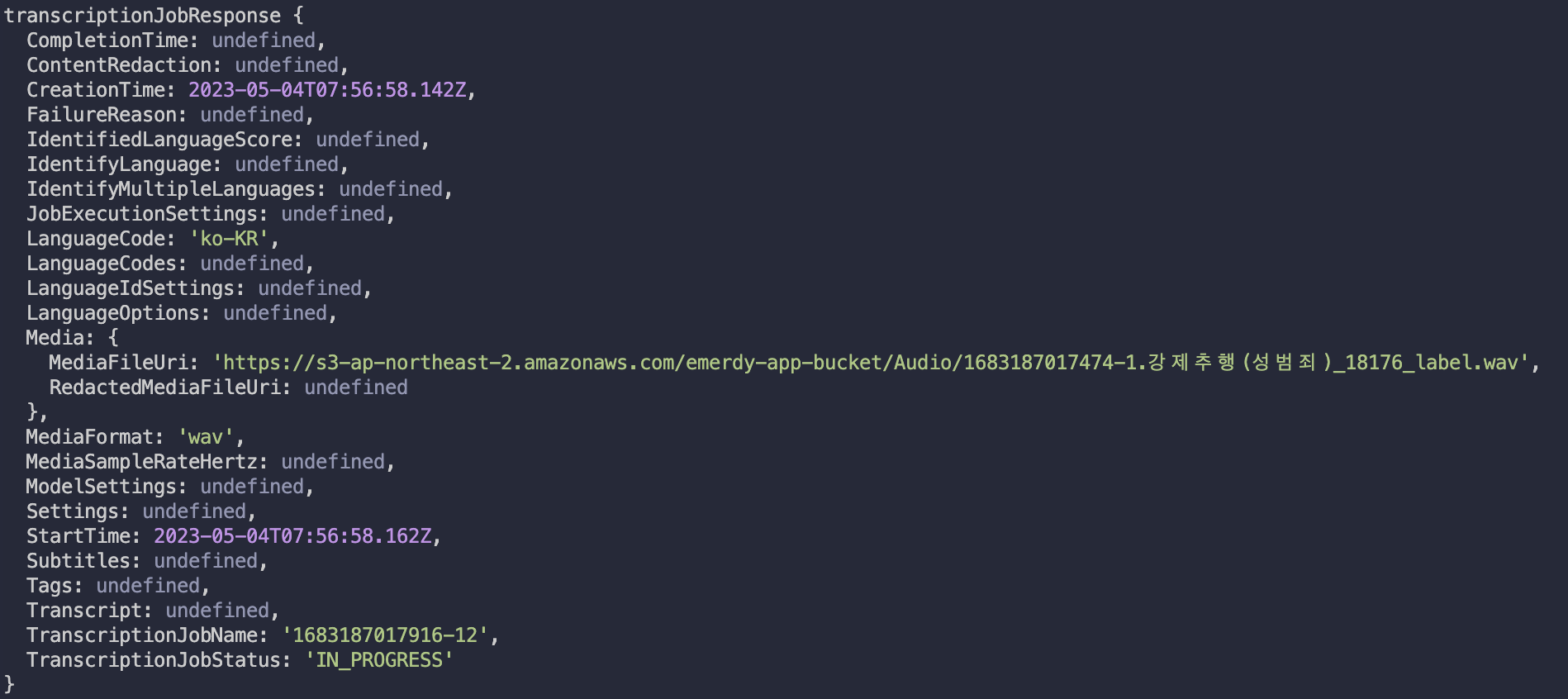
프로퍼티의 설명은 아래 링크를 참고해주세요.
TranscriptionJob @aws-sdk/client-transcribe
위 프로퍼티 중 가장 중요한 프로퍼티는 TranscriptionJobStatus입니다. 이름 그대로 작업의 시작 상황을 알려주는 프로퍼티입니다. 여기서 중요한 것은 TranscriptionJob의 완료 여부를 반환하지 않는다는 것입니다. 따라서 우리는 TranscriptionJobStatus가 COMPLETED가 되는 방법을 알기 위해서는 서버가 AWS Transcribe에 일정 주기마다 완료 여부를 요청할 수 밖에 없습니다.
Transcribe 작업 완료 여부 체크
private async getTranscribeResult(transcribeClient: TranscribeClient,transcriptionJobName: string): Promise<TranscriptionJob> {
try {
const param = {
TranscriptionJobName: transcriptionJobName,
};
const transcribeCommand = new GetTranscriptionJobCommand(param);
let i = 0;
let job: GetTranscriptionJobCommandOutput;
while (i < 60) {
job = await transcribeClient.send(transcribeCommand);
const job_status = job['TranscriptionJob']['TranscriptionJobStatus'];
if (['COMPLETED', 'FAILED'].includes(job_status)) {
if (job_status === 'COMPLETED') {
return job['TranscriptionJob'];
}
} else {
console.log(`Waiting for ${transcriptionJobName}. Current status is ${job_status}`);
}
i++;
await new Promise((resolve) => {
setTimeout(resolve, 1000);
});
}
} catch (e) {
console.log(e);
...
}
}
Transcription 작업 완료 여부를 확인하기 위해서는 TranscriptionJobName 파라미터가 필수입니다.
자세한 API 설명은 아래 링크를 참고해주세요.
GetTranscriptionJobCommand @aws-sdk/client-transcribe
그리고 1초의 대기시간 후 API 요청을 총 60번하여 최대 1+$\alpha$분 동안 Transcription 작업 완료 여부를 확인하도록 하였습니다.
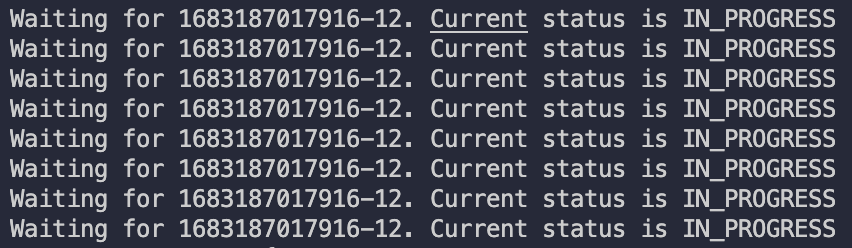
TranscriptionJobStatus가 COMPLETED가 되면 TranscriptionJob을 리턴합니다.
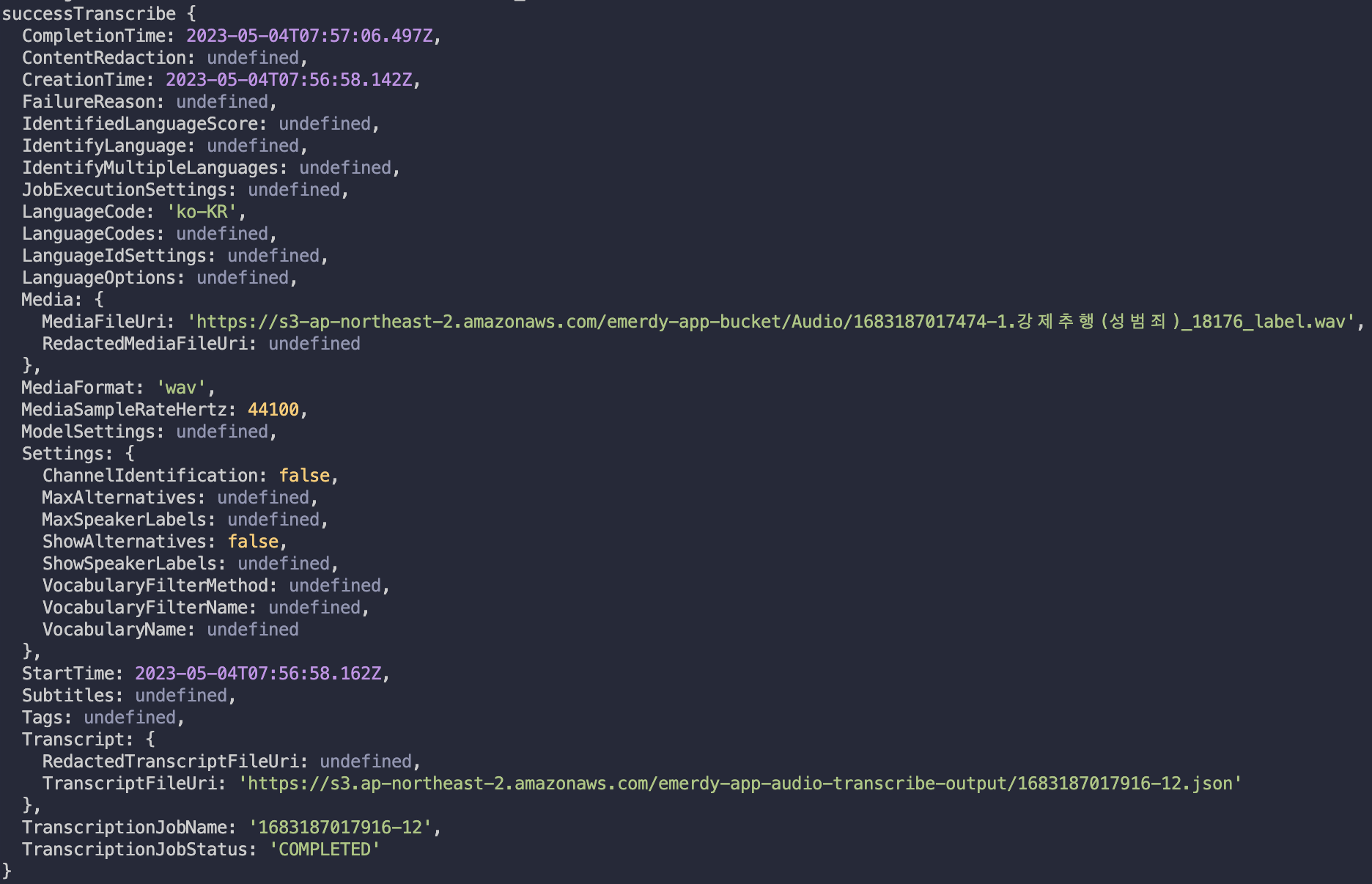
TranscriptionJob의 프로퍼티 중 Transcript의 TranscriptFileUri 프로퍼티를 통해 추출된 텍스트가 담겨있는 json 파일을 확인할 수 있습니다.
TranscriptFile JSON S3 객체 조회
private async getTranscriptFile(keyName: string): Promise<string> {
try {
const params = {
Bucket: 'emerdy-app-audio-transcribe-output',
Key: `${keyName}.json`,
};
const transcriptFile = await this.s3.getObject(params).promise();
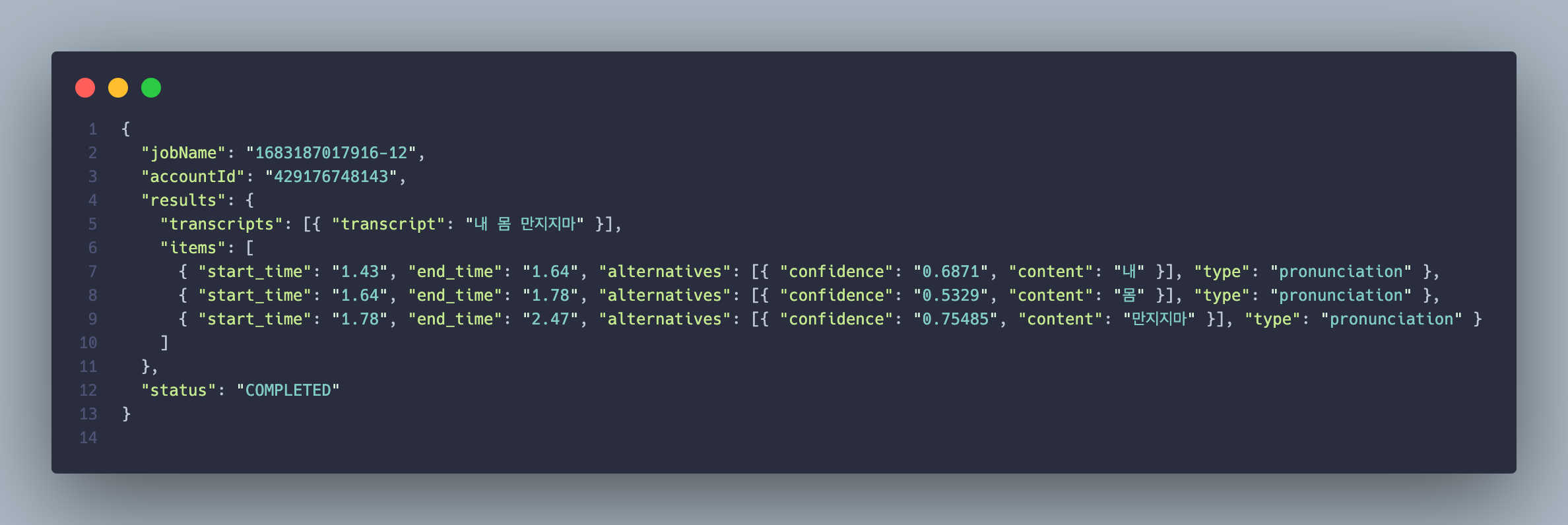
const transcripts = JSON.parse(transcriptFile.Body.toString('utf-8')).results.transcripts[0]
.transcript;
const text: string = transcripts === '' ? 'empty' : transcripts;
return text;
} catch (e) {
console.log(e);
...
}
}
그 이후는 매우 간단합니다. S3 객체 조회 API를 통해 Transcribe output 저장 버킷 이름과 TranscriptionJobName 을 통해 TranscriptFile JSON S3 객체를 요청한 후 JSON 형태로 파싱하면 됩니다.